Why LinkedIn Built a Unified Data Science Platform For AI

As one of the leading global professional networks today, LinkedIn generates a prodigious amount of data. According to details from last year, this adds up to one exabyte – or one million terabytes, stored across multiple Hadoop clusters. This includes a massive 10,000-node cluster containing a billion objects with an average latency of lower than 10 milliseconds.
But while LinkedIn knows a thing or two about large-scale data science, it turns out that having multiple data teams working on disparate projects lends to its own set of problems. Much like in IT, the proliferation of tools and individual projects can cause sprawl and fragmentation to creep in.
Growing demand for data science
In a blog post, LinkedIn engineers Varun Saxena, Harikumar Velayutham, and Balamurugan Gangadharan outlined the motivation behind the creation of Darwin, an acronym for “Data science and Artificial intelligence Workbench at LinkedIn”.
According to them, one challenge can best be described as a poor developer experience and hurt overall productivity as users juggle multiple tools for data analysis and collaboration.
The other is a fragmented toolset that makes it challenging to share prior work and ensure that security policies are followed.
“Another [pre-Darwin] problem was fragmentation in tooling due to historical usage and personal preferences, which led to knowledge fragmentation, lack of easy discoverability of prior work, and difficulty in sharing results with partners,” they wrote.
“Moreover, making each tool compliant with LinkedIn's privacy and security policies, especially when tools were used locally, resulted in an ever-increasing overhead.”
A unified tool
Solving these challenges called for a way to unify the scattered tooling and AI workflows. To achieve this, LinkedIn decided to build a unified, one-stop tool for the organization for data scientists, AI engineers, data analysts, business analysts, and even product managers to work together.
This is much harder than it sounds and entails identifying the various personas that will access the system across data exploration and transformation, visualization, and productionizing.
Beyond requirements around collaboration and distribution of data insights, the LinkedIn team is also clear on integration with other tools and platforms, and to develop the inherent extensibility to democratize the platform such that it can be integrated with independent solutions.
“We wanted DARWIN to leverage the power of other tools in the ecosystem and integrate with them to enable different user personas to have a unified experience of building ML pipelines, metric authoring, and data catalog in a single tool.”
“We wanted [to]… have support for: different environments having different libraries, multiple languages for development, integration with various query engines and data sources, custom extensions, and kernels. We aimed to go beyond merely creating a notebook and to allow users to bring their own app (BYOA) and onboard it to [Darwin].”
Putting it together
According to LinkedIn, the Darwin architecture works with various database engines through languages such as Python, SQL, R, and Scala for Spark, along with direct access to data on HDFS (Hadoop Distributed File System). The objective is to provide access to data across LinkedIn irrespective of the platform it is stored in, says the LinkedIn team.
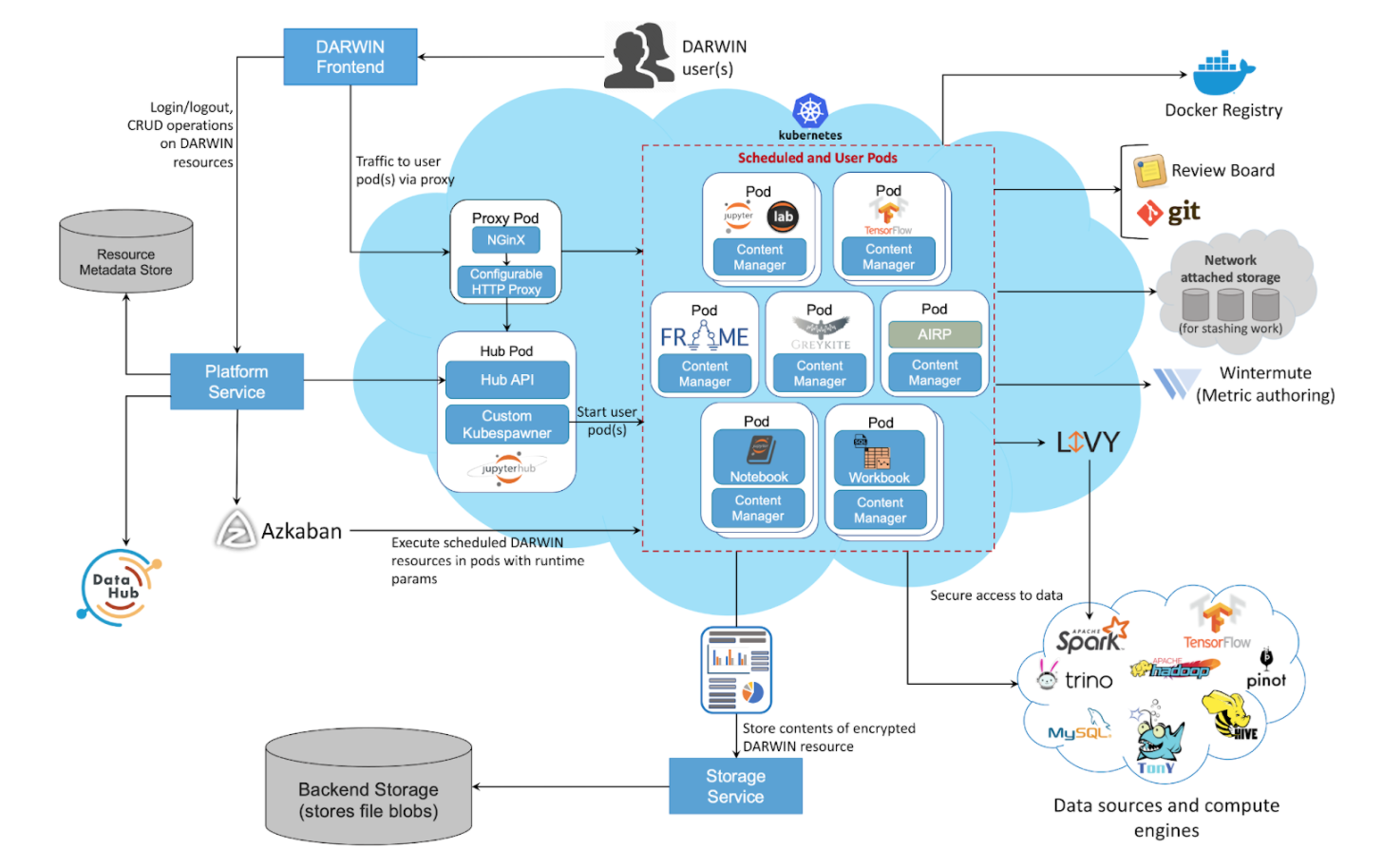
The platform is built on top of Kubernetes for scalability and to give users a dedicated and isolated environment of their own. The use of containers makes it possible for other users and teams to extend the platform by packaging different libraries and applications to effectively “Build Your Own Application” (BYOA) on Darwin.
The concurrent user environments are managed with JupyterHub, which supports multiple environments and offers pluggable authentication that is integrated with the LinkedIn authentication stack. User server lifecycle also means that user servers can be shut down due to inactivity, among other features needed by the team.
What’s next
Darwin is currently in use by over 1,400 active users, with the user base growing by over 70% in the past year. What is interesting is how this includes SRE (Site Reliability Engineering), Trust, and key product teams – not just your typical data science or AI experts.
Much remains to be done, though. Some of the ideas include publishing dashboards and custom applications and supporting rich code-free visualization capabilities to better support citizen data scientists. Git and version support are also mooted, and users will also be able to clone their projects and back them up directly to network-attached storage for greater privacy and control.
The team says it plans to eventually open source DARWIN for use by other organizations.
Paul Mah is the editor of DSAITrends. A former system administrator, programmer, and IT lecturer, he enjoys writing both code and prose. You can reach him at [email protected].
Image credit: iStockphoto/wachira khurimon






